Overview
Galvatron is an automatic distributed training system designed for Transformer models, including Large Language Models (LLMs). It leverages advanced automatic parallelism techniques to deliver exceptional training efficiency. This repository houses the official implementation of Galvatron-2, our latest version enriched with several new features.
Key Features
(1) Enhanced Efficiency via Automatic Parallelism
Enlarged Parallelism Search Space
Incorporate multiple popular parallelism dimensions of distributed training, including DP (Data Parallelism), SDP (Sharded Data Parallelism, support ZeRO-1, ZeRO-2 and ZeRO-3), PP (Pipeline Parallelism, support both GPipe & Pipedream-flush / 1F1B-flush), TP (Tensor Parallelism), SP (Sequence Parallelism, support Megatron-SP and Deepspeed-Ulysses). Also incorporate CKPT (Activation Checkpointing) as a special parallelism dimension.
Fine-grained Hybrid Parallelism
Galvatron’s approach to hybrid parallelism represents a significant advancement in distributed training optimization. Rather than applying a one-size-fits-all strategy, the system enables layer-wise parallelization, allowing each transformer layer to utilize an independent combination of parallel strategies. This granular approach ensures optimal resource utilization by adapting to the specific computational and memory requirements of each layer.
The system dynamically combines multiple parallelism types, carefully considering the trade-offs between computation, memory usage, and communication overhead. This hybrid approach is particularly powerful when dealing with complex model architectures, where different layers may benefit from different parallelization strategies.
Efficient Automatic Parallelism Optimization
The heart of Galvatron’s efficiency lies in its sophisticated optimization engine. Through careful cost modeling, the system accurately estimates computation requirements, predicts memory usage patterns, and models communication overhead for different parallelization strategies. This comprehensive modeling enables intelligent decision-making in strategy selection.
The optimization process employs advanced search algorithms with dynamic programming that consider multiple objectives simultaneously, including memory efficiency and communication costs. The system automatically adapts to hardware constraints while ensuring optimal performance.
(2) Versatility
Galvatron’s versatility extends across the entire spectrum of Transformer architectures. In the realm of language models, it excels at handling everything from traditional BERT-style encoders and GPT decoders to complex T5-style encoder-decoder models. For Large Language Models (LLMs), the system provides specialized optimizations that enable efficient training of models with trillions of parameters, carefully managing memory and computational resources.
The system’s capabilities extend beyond language models to vision transformers. Galvatron maintains its efficiency while adapting to the unique requirements of each architecture. In the future, Galvatron will also support multi-modal architectures.
(3) User-Friendly Interface
Despite its sophisticated underlying technology, Galvatron prioritizes user accessibility. Users can begin training with minimal code changes, supported by comprehensive documentation and practical examples. The system also offers seamless integration with dataloader of popular framework , alongside robust checkpoint management capabilities, making it a practical choice for both research and production environments.
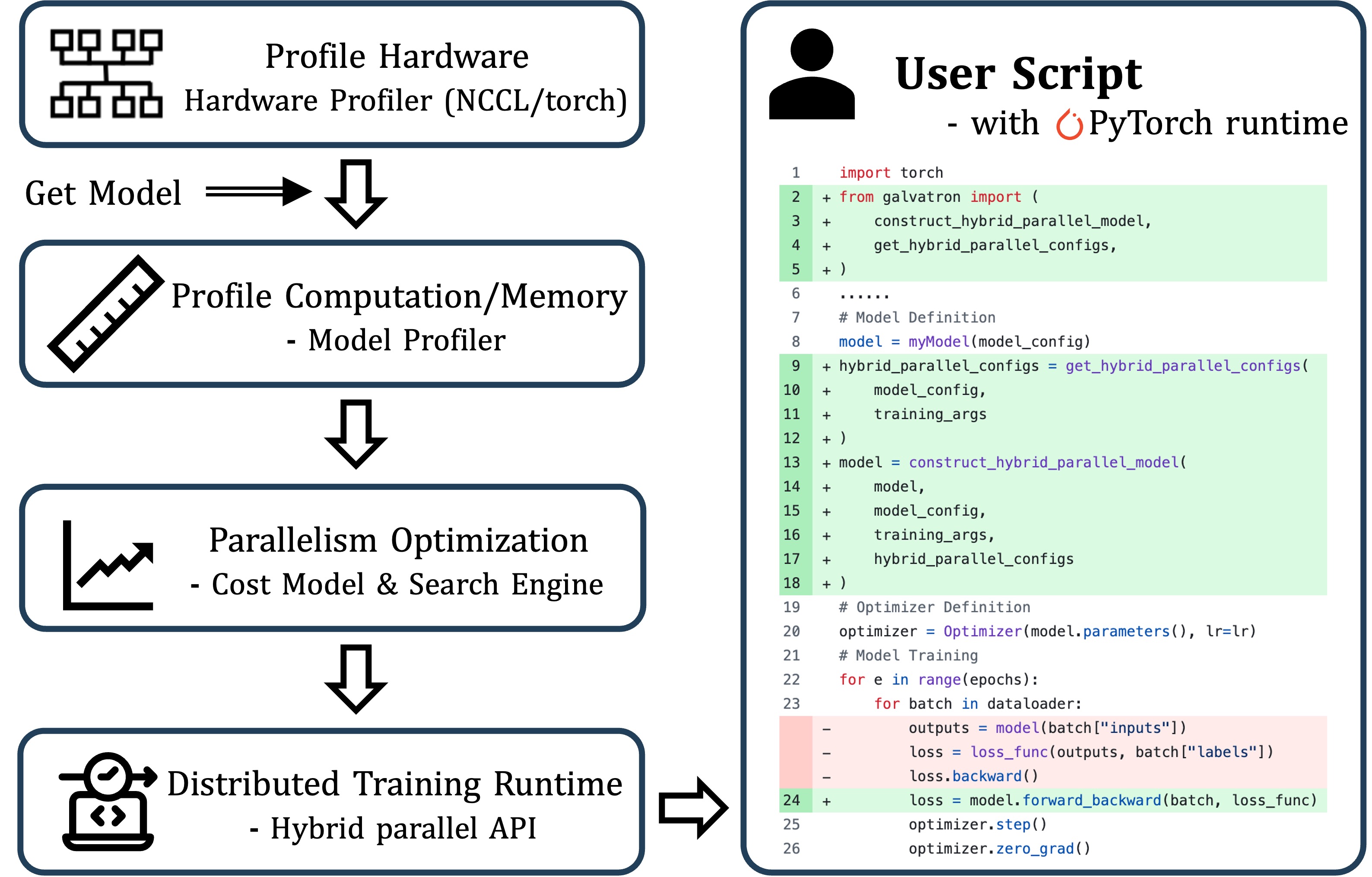
System Architecture
Galvatron’s architecture consists of three tightly integrated core modules that work together to deliver efficient distributed training:
(1) Galvatron Profiler
The Profiler serves as the foundation of the system, conducting comprehensive analysis of both hardware capabilities and model characteristics. On the hardware side, it measures inter-device communication bandwidth and computational throughput of each device. For model profiling, it analyzes computation patterns, memory requirements, and communication needs of different model components. This detailed profiling information forms the basis for intelligent strategy decisions.
(2) Galvatron Search Engine
The Search Engine represents the brain of the system, leveraging the profiling data to discover optimal parallelization strategies. It employs sophisticated algorithms to explore the vast space of possible parallel configurations and automatically determine the most efficient combination of parallelism strategies for each layer of the model.
(3) Galvatron Runtime Framework
The Runtime Framework implements the execution layer, translating the high-level parallelization strategies into efficient distributed operations. The framework provides a robust and flexible execution environment that adapts to different hardware configurations and model architectures.
Integration and Workflow
These three modules work seamlessly together to simplify the distributed training process. Users only need to provide hardware environment and Transformer model configuration.
The system automatically handles all aspects of distributed training optimization, from initial profiling through strategy selection to efficient execution. This architecture ensures both ease of use and high performance, making sophisticated distributed training accessible to a broader range of users while maintaining the flexibility needed for advanced applications.
Through this modular design, Galvatron achieves a balance between automation and customization, enabling both simple deployment for standard cases and detailed control for specialized requirements.